When NHibernate with Fluent NHibernate work, it’s a beautiful thing. They almost make building applications that use a relational database painless. However, sometimes you run into something that costs a couple of developers the better part of a day and it makes you want to scream. The team I’m on had one of those days as a result of trying to refactor our database to fit better with our business instead of NHibernate.
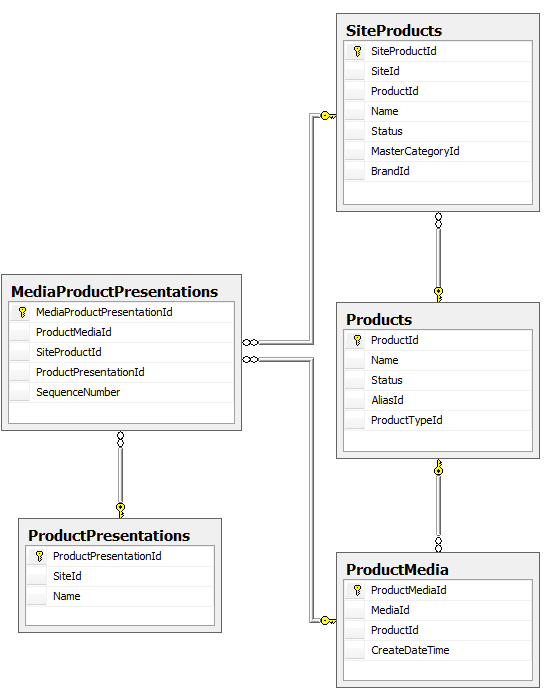
Here’s a portion of our original database structure:
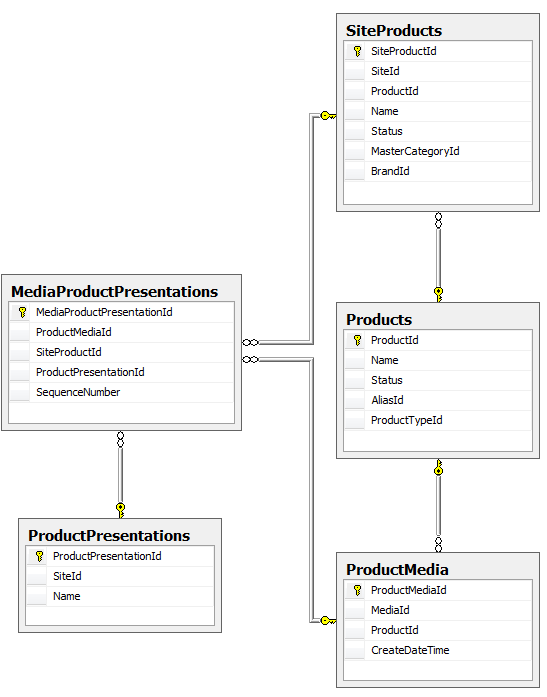
The changes we wanted to make fell into two categories. First, we wanted to rename some tables to better align with the business vocabulary. For example, the table ProductMedia would become MediaPool because that’s what marketing called it. The second change turned out to be more problematic.
Houston, We Have a Problem
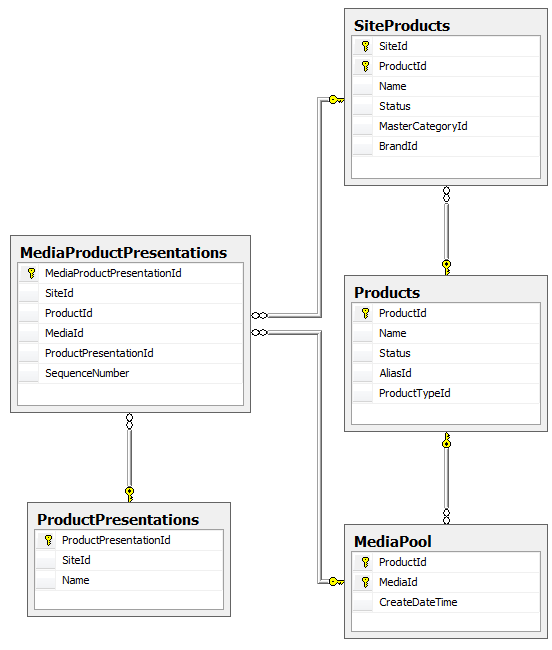
Some of our entities actually represent the relationship between two other entities. For example, we have a SiteProduct that represents a Product on a Site. When we first designed the database, we setup the relationship entites with a single field surrogate key: A unique, automatically generated ID that only exists to serve the database. The problem was it had no meaning to the business so our screens tended to know the SiteId and the ProductId but not the SiteProductId. This forced us to constantly join or lookup the SiteProduct table to get the SiteProductId so we could get to the data we needed to perform work. We wanted to eliminate those surrogate keys and use the combination of SiteId and ProductId as a composite key instead. We had similar circumstances in a couple of other relationship tables that we also wanted to improve. We ended up with this:
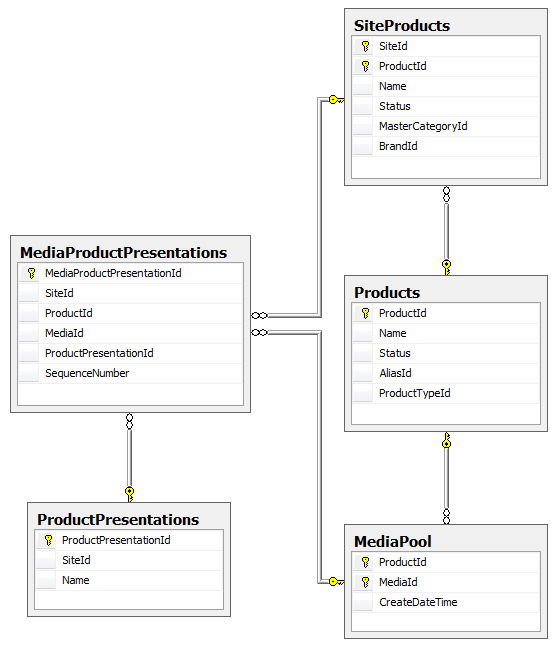
After reworking our entities and Fluent NHibernate maps to mirror our new structure, we ran into the following rather cryptic exception when running our unit test suite against SQLLite:
System.ArgumentOutOfRangeException : Index was out of range. Must be non-negative and less than the size of the collection. Parameter name: index
The problem was maps like this one:
public class MediaProductPresentationMap : ClassMap
{
public MediaProductPresentationMap()
{
Table("MediaProductPresentations");
Id(x => x.Id, "MediaProductPresentationId").GeneratedBy.Identity().UnsavedValue(0);
Map(x => x.SequenceNumber).Not.Nullable();
References(x => x.Presentation, "ProductPresentationId").Not.Nullable().Cascade.None();
References(x => x.MediaInPool).Columns("MediaId", "ProductId").Not.Nullable().Cascade.None();
References(x => x.SiteProduct).Columns("SiteId", "ProductId").Not.Nullable().Cascade.None();
}
}
Notice that ProductId is one component of the composite key for MediaInPool and one component of the composite key for SiteProduct. As it turns out, NHibernate simply cannot deal with one field being mapped twice. The only work around mentioned anywhere is to make at least one of the references read only. Unfortunately, that doesn’t work in this case because each of the keys consists of two fields. If we make the reference to MediaInPool read only, the MediaId does not get set and the insert fails; If we make the SiteProduct reference read only, the insert fails with a null SiteId.
A couple members of the team looked for solutions all afternoon. I got involved as well and we just could not find a good answer. After dinner, I sat down and examined the issue one more time and came up with a bit of a hack to solve the problem. The application needed NHibernate to set all the ID fields when inserting a new MediaProductPresentation. It also needed to be able to traverse the references when reading. However, since the MediaInPool and SiteProduct already exist before the application tries to add a MediaProductPresentation, the references could be read only as long as there was another way to tell NHibernate to update those ID fields.
The Solution
The solution required changes to both the entity and the map. First the entity:
public class MediaProductPresentation
{
public virtual string Id { get; set; }
public virtual SiteProduct SiteProduct { get; set; }
public virtual ProductPresentation Presentation { get; set; }
public virtual MediaInPool MediaInPool { get; set; }
public virtual int SequenceNumber { get; set; }
public virtual int MediaId { get { return MediaInPool.Media.Id; } protected set { } }
/// These two properties exist solely to support NH persistence. On a save, these are the ones that are actually persisted in the NH map.
/// They should not ever need to be exposed to other classes.
protected internal virtual int SiteId { get { return SiteProduct.SiteId; } protected set { } }
protected internal virtual int ProductId { get { return SiteProduct.ProductId; } protected set { } }
protected MediaProductPresentation() {}
public MediaProductPresentation(SiteProduct siteProduct, ProductPresentation presentation, MediaInPool mediaInPool, int sequenceNumber)
{
SiteProduct = siteProduct;
Presentation = presentation;
MediaInPool = mediaInPool;
SequenceNumber = sequenceNumber;
}
}
The entity has both objects to represent the references for the read case (e.g. SiteProduct) and ID fields for the references to support the write case (e.g. SiteId, ProductId). The ID fields use a clever pattern taught to me by one of my colleagues, Tim Coonfield. Although NHibernate can see them, other classes in the application cannot.
With the entity setup correctly, the map is easy though it looks a little strange:
public class MediaProductPresentationMap : ClassMap
{
public MediaProductPresentationMap()
{
Table("MediaProductPresentations");
Id(x => x.Id, "MediaProductPresentationId").GeneratedBy.Identity().UnsavedValue(0);
Map(x => x.SequenceNumber).Not.Nullable();
Map(x => x.ProductId).Not.Nullable();
Map(x => x.MediaId).Not.Nullable();
Map(x => x.SiteId).Not.Nullable();
References(x => x.Presentation, "ProductPresentationId").Not.Nullable().Cascade.None();
References(x => x.MediaInPool).Columns("MediaId", "ProductId").Not.Nullable().Cascade.None().Not.Insert().Not.Update().ReadOnly();
References(x => x.SiteProduct).Columns("SiteId", "ProductId").Not.Nullable().Cascade.None().Not.Insert().Not.Update().ReadOnly();
}
}
The map tells NHibernate to ignore the object references when inserting or updating. Instead, NHibernate sets the various foreign key reference IDs directly.
It May Not be Pretty, But It Works
It’s a shame that NHibernate is not smart enough to reference multiple tables that share common elements in their composite keys. As our data architect put it, this is why almost everybody that uses NHibernate sticks to single field keys and uses surrogate keys on relationship tables. This work around makes it possible to use composite keys where they make sense without fear. I know it’s not exactly beautiful, but, at least for us, it was a small price to pay to have the database structure align better with the business.




You must be logged in to post a comment.